pip install -r requirements.txt -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
Vincent Zhong
No results found
StackEdit 服务器搭建
Stackedit是一款很棒的在线Markdown editor。我们现在把它搭建到本地,让其可以离线使用。
安装node.js
前往node.js官网安装node.js
下载Stackedit
前往github下载 https://github.com/benweet/stackedit 然后解压
安装依赖包
1.命令行切换到Stackedit目录,执行npm install
2.执行 npm install -g bower
3.执行bower install
编写快捷方式
保存为后缀名为.bat的文件123e:cd E:\Program Files (x86)\stackeditnode server.js
说说JavaScript里面的面向对象编程
创建对象
Javascript是一种基于对象(object-based)的语言,你遇到的所有东西几乎都是对象。但是,它又不是一种真正的面向对象编程(OOP)语言,因为它的语法中没有class(类)。
工厂模式
|
|
缺点:无法解决对象识别问题
构造函数模式
|
|
问题:person1与person2的sayName()方法不是同一个Function实例。
可以这样解决。123456789function Person(name, age, job){ this.name = name; this.age = age; this.job = job; this.sayName = sayName; //这是指针,需是全局函数}function sayName(){ alert(this.name);}
问题:分开写好麻烦,函数需是全局的。毫无封装性可言
原型模式
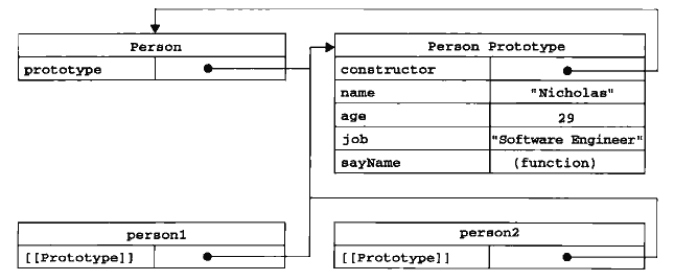
我们创建的每个函数都有一个prototype(原型)属性,这个属性是一个指针,指向一个对象。而这个对象的用途是包含可以由特定类型的所有实例共享的属性和方法。如果按照字面意思来理解,那么prototype就是通过调用构造函数而创建的那个对象实例的原型对象。使用原型对象的好处是可以让所有对象实例共享它所包含的属性和方法。换句话说,不必在构造函数中定义对象实例的信息,而是可以将这些信息直接添加到原型对象中12345678910111213function Person(){}Person.prototype.name = "Nicholas";Person.prototype.age = 29;Person.prototype.job = "Software Engineer";Person.prototype.sayName = function(){ alert(this.name);};var person1 = new Person();person1.sayName(); //"Nicholas"var person2 = new Person();person2.sayName(); //"Nicholas"alert(person1.sayName == person2.sayName); //true
新对象的属性和方法是由所有实例共享的。
理解原型对象
无论什么时候,只要创建了一个新函数,就会根据一组特定的规则为该函数创建一个prototype属性,这个属性指向函数的原型对象在默认情况下,所有原型对象都会自动获得一个constructor(构造函数)属性,这个属性包含一个指向prototype属性所在函数的指针。就拿前面的例子来说,Person.prototype.constructor指向Person而通过这个构造函数我们还可继续为原型对象添加其他属性和方法。
|
|
创建了自定义的构造函数之后,其原型对像默认只会取得constructor属性;至于其他方法,则都是从Object继承而来的。当调用构造函数创建一个新实例后,该实例的内部将包含一个指针[[Prototype]](内部属性),指向构造函数的原型对象。在脚本中没有标准的方式访问[[Prototype]], Flrefox、Safan和Chrome在每个对象上都支持一个属性proto;而在其他实现中,这个属性对脚本则是完全不可见的。这个连接存在于实例与构造函数的原型对象之间,而不是存在于实例与构造函数之间。
首先寻找实例的属性,然后再寻找原型的属性。12345678910111213function Person(){}Person.prototype.name = "Nicholas";Person.prototype.age = 29;Person.prototype.job = "Software Engineer";Person.prototype.sayName = function(){ alert(this.name);};var person1 = new Person();var person2 = new Person();person1.name = "Greg";alert(person1.name); //"Greg" ?from instancealert(person2.name); //"Nicholas" ?from prototype
使用hasOwnProperty()方法检测一个属性是存在实例中,还是存在原型中。
in操作符,无论属性存在示例中还是原型中12345678910111213141516171819202122232425function Person(){ } Person.prototype.name = "Nicholas"; Person.prototype.age = 29; Person.prototype.job = "Software Engineer"; Person.prototype.sayName = function(){ alert(this.name); }; var person1 = new Person(); var person2 = new Person(); alert(person1.hasOwnProperty("name")); //false alert("name" in person1); //true person1.name = "Greg"; alert(person1.name); //"Greg" ?from instance alert(person1.hasOwnProperty("name")); //true alert("name" in person1); //true alert(person2.name); //"Nicholas" ?from prototype alert(person2.hasOwnProperty("name")); //false alert("name" in person2); //true delete person1.name; alert(person1.name); //"Nicholas" - from the prototype alert(hasPrototypeProperty(person, "name")); //false alert(person1.hasOwnProperty("name")); //false alert(hasPrototypeProperty(person1, "name")); //true alert("name" in person1); //true
在使用for-in循环时,返回的是所有能够通过对象访问的、可枚举的(enumerated)属性,其中既包括存在于实例中的属性,也包括存在于原型中的属性。屏蔽了原型中不可枚举属性(即将[[Enumerable]]标记为false属性)的实例属性也会在for-in循环中返回,因为根据规定,所有开发人员定义的属性都是可枚举的一一只有在IE8及更早版本中外。
Object.keys()
接受一个对象作为参数,返回一个包含所有可枚举属性的字符串数组12var keys = Object.keys(Person.prototype);alert(keys); //"name,age,job,sayName"
Obejct.getOwnProperyNames()
取得所有实例属性,无论是否枚举12var keys = Object.getOwnPropertyNames(Person.prototype);alert(keys); //"constructor,name,age,job,sayName"
更简单的原型语法
|
|
在上面的代码中我们将person.prototype设置为等于一个以对象字面量形式创建的新对象最终结果相同,但有一个例外:constructor属性不再指向person了。前面曾经介绍过,每创建一个函数,就会同时创建它的prototype对象,这个对象也会自动获得constructor属性。而我们在这里使用的语法,本质上完全重写了默认的prototype对象因此constructor属性也就变成了新对象的constructor属性(指向Object构造函数),不再指向person函数。此时,尽管instanceof操作符还能返回正确的结果,但通过constructor已经无法确定对象的类型了1234alert(friend instanceof Object); //truealert(friend instanceof Person); //truealert(friend.constructor == Person); //falsealert(friend.constructor == Object); //true
重设constructor属性会导致他的[[Enumerable]]特性被设为true。默认是false123456789Person.prototype = { constructor : Person, name : "Nicholas", age : 29, job: "Software Engineer", sayName : function () { alert(this.name); }};
问题:原型中所有属性都是被实例们共享的。对于那些包含基本值的属性还说得过去(通过在实例上添加一个同名属性,可以隐藏原型中对应的属性),然而对于包含引用类型值的属性来说就有问题了123456789101112131415161718function Person(){}Person.prototype = { constructor: Person, name : "Nicholas", age : 29, job : "Software Engineer", friends : ["Shelby", "Court"], sayName : function () { alert(this.name); }};var person1 = new Person();var person2 = new Person();person1.friends.push("Van");alert(person1.friends); //"Shelby,Court,Van"alert(person2.friends); //"Shelby,Court,Van"alert(person1.friends === person2.friends); //true
组合使用构造函数模式和原型模式
构造函数模式用于定义实例属性,而原型模式用于定义方法和共享的属性。12345678910111213141516171819function Person(name, age, job){ this.name = name; this.age = age; this.job = job; this.friends = ["Shelby", "Court"];}Person.prototype = { constructor: Person, sayName : function () { alert(this.name); }};var person1 = new Person("Nicholas", 29, "Software Engineer");var person2 = new Person("Greg", 27, "Doctor");person1.friends.push("Van");alert(person1.friends); //"Shelby,Court,Van"alert(person2.friends); //"Shelby,Court"alert(person1.friends === person2.friends); //falsealert(person1.sayName === person2.sayName); //true
动态原型模式
把所有信息息都封装在了构造函数中,而通过在构造数中初始化原型(仅在必要的情况下),又保持了同时使用构造函数和原型的优点。1234567891011121314function Person(name, age, job){ //properties this.name = name; this.age = age; this.job = job; //methods if (typeof this.sayName != "function"){ Person.prototype.sayName = function(){ alert(this.name); }; }}var friend = new Person("Nicholas", 29, "Software Engineer");friend.sayName();
寄生构造函数模式
创建一个函数,该函数的作用仅仅是封装对象的代码,然后返回新创建的对象123456789101112function Person(name, age, job){ var o = new Object(); o.name = name; o.age = age; o.job = job; o.sayName = function(){ alert(this.name); }; return o;}var friend = new Person("Nicholas", 29, "Software Engineer");friend.sayName(); //"Nicholas"
这个模式可以在特殊情况下用来为对象创建构造函数。例如,由于不能直接修改Array构造函数,因此可以123456789101112131415function SpecialArray(){ //create the array var values = new Array(); //add the values values.push.apply(values, arguments); //assign the method values.toPipedString = function(){ return this.join("|"); }; //return it return values; }var colors = new SpecialArray("red", "blue", "green");alert(colors.toPipedString()); //"red|blue|green"alert(colors instanceof SpecialArray);//false
返回的对象与构造函数或者与构造函数的原型属性之间没有关系;也就是说,构造函数返回的对象与在构造函数外部创建的对象没有什么不同。因此,不能用instanceof来确定对象类型。
稳妥构造函数模式
所谓稳妥对象,指的是没有公共属性。1234567function Person(name, age, job){ var o = new Object(); o.sayName = function(){ alert(this.name); }; return o;}
在以这种模式创建的对象中,除了使用方法之外,没有其他办法访问属性值。
在某些情况下使用。
继承
通常OO语言都支持两种继承方式:
接口继承:只继承方法签名
实现继承:继承实际的方法
原型链
基本思想是利用原型让一个引用类型继承另一个引用类型的属性和方法。
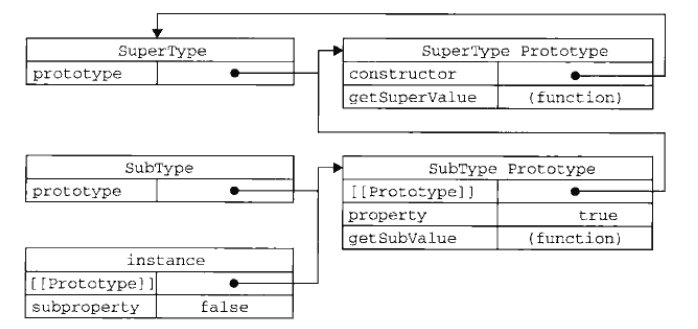
假如我们让原型对象等于另一个类型的实例,此时的原型对象将包含一个指向另一个原型的指针,相应地,另一个原型中也包含着一个指向另一个构造函数的指针。如此层层递进。
|
|
实例的本质是重写原型对象,代之以一个新类型的实例。换句话说,原来存在于SuperType的实例中的所有属性和方法,现在也存在于SubType.prototype中。只不过子类中同名属性会覆盖父类中的同名属性。1234567891011121314151617function SuperType(){ this.property = true; } SuperType.prototype.getSuperValue = function(){ return this.property; }; function SubType(){ this.property = false; } //inherit from SuperType SubType.prototype = new SuperType(); SubType.prototype.getSubValue = function (){ return this.property; }; var instance = new SubType(); alert(instance.getSuperValue()); //false alert(instance.getSubValue()); //false
所有的函数的默认原型都是Object的实例,因为默认原型都会有一个内部指针,指向Object.prototype。
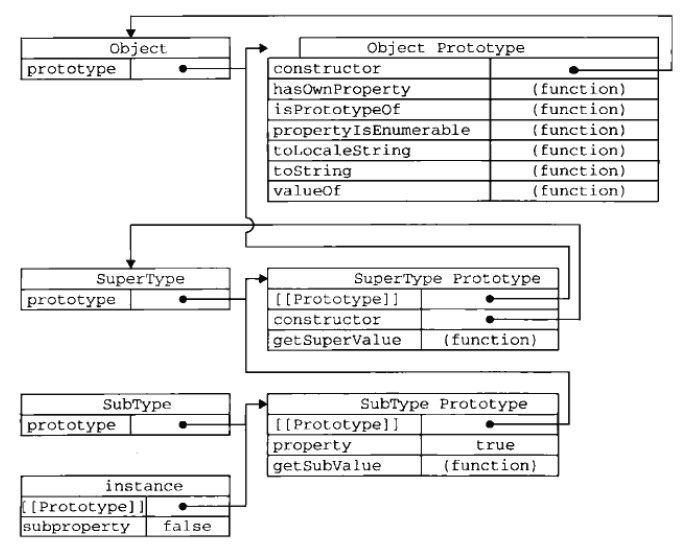
重写父类的方法
|
|
使用对象字面量创建原型方法,会重写原型链。
|
|
原型链的问题
- 包含引用类型值的原型属性会被所有实例共享
- 在创建子类型的实例时,不能向父类的构造函数中传递参数。实际上,应该说是没有办法在不影响所有对象实例的情况下,给父类的构造函数传递参数
借用构造函数
在子类构造函数的内部调用父类的构造函数。123456789101112131415161718function SuperType(name){ this.name = name; this.sayName = function () { return this.name }}function SubType(){ //在新创建的SubType实际的环境下调用了SuperType的构造函数,SubType的每个实例都会有自己的属性副本 SuperType.call(this, "Nicholas"); //instance property this.age = 29;}var instance = new SubType();alert(instance.name); //"Nicholas";alert(instance.age); //29var instance = new SubType();var instance2 = new SubType()alert(instance.sayName === instance2.sayName) //false
问题:
- 方法都在构造数中定义,因此函数复用就无从谈起了。
- 在超类型的原型中定义的方法,对子类型而言也是不可见的,结果所有类型都只能使用构函数模式。
组合继承
将原型链和借用构造函数的技术组合到一块。最常用的继承12345678910111213141516171819202122232425function SuperType(name){ this.name = name; this.colors = ["red", "blue", "green"];}SuperType.prototype.sayName = function(){ alert(this.name);};function SubType(name, age){ SuperType.call(this, name); this.age = age;}SubType.prototype = new SuperType();SubType.prototype.sayAge = function(){ alert(this.age);};var instance1 = new SubType("Nicholas", 29);instance1.colors.push("black");alert(instance1.colors); //"red,blue,green,black"instance1.sayName(); //"Nicholas";instance1.sayAge(); //29var instance2 = new SubType("Greg", 27);alert(instance2.colors); //"red,blue,green"instance2.sayName(); //"Greg";instance2.sayAge(); //27alert(instance.sayName === instance2.sayName) //true
原型式继承
先创建一个临时性的构造函数,然后将传入的对象作为这个构造函数的原型,最后返回了这个临时类型的一个新实例。
本质上,object()对传入其中的对象执行了一次浅复制123456789101112131415161718192021222324252627 function object(o) { function F() {} F.prototype = o return new F() } var person = { name: "Nicholas", friends: ["Shelby", "Court", "Van"] }; var anotherPerson = object(person); anotherPerson.name = "Greg"; anotherPerson.friends.push("Rob"); var yetAnotherPerson = object(person); yetAnotherPerson.name = "Linda"; yetAnotherPerson.friends.push("Barbie"); alert(person.friends); //"Shelby,Court,Van,Rob,Barbie"Object.create()方法 var person = { name: "Nicholas", friends: ["Shelby", "Court", "Van"] }; var anotherPerson = Object.create(person, { name: { value: "Greg" } }); alert(anotherPerson.name); //"Greg"
在没有必要兴师动众地创建构造函数,而只想让一个对象与另一个对象保持类似的情况下使用。
包含引用类型值的属性始终都会共享相应的值
寄生式继承
创建一个仅用于封装继承过程的函数,该函数在内部以某种方式来增强对象,最后像真的是它做了所有工作一样返回对象12345678910111213141516171819// 相当于继承 function object(o) { function F() {} F.prototype = o return new F() } function createAnother(original) { var clone = object(original) clone.sayHi= function () { alert("hi") } return clone } var person = { name: "Nicholas", friends: ["Shelby", "Court", "Van"] }; var anotherPerson = createAnother(person) anotherPerson.sayHi()
问题:不能函数复用
寄生组合式继承
组合式继承最大的问题就是无论什么情况下,都会调用两次构造函数:一次是在创建子类原型的时候,另一次是在子类构造函数内部。12345678910111213function SuperType(name){ this.name = name; this.colors = ["red", "blue", "green"];}SuperType.prototype.sayName = function(){ alert(this.name);};function SubType(name, age){ SuperType.call(this, name); this.age = age;}SubType.prototype = new SuperType();//详见组合继承的代码
第一次调用SuperType构造函数时。SubType.prototype会得到两个属性,name和colors;它们是SuperType的实例属性
第二次调用SuperType构造函数时。在新对象上创建了实例属性name和colors,这两个属性屏蔽了原型中的两个同名属性
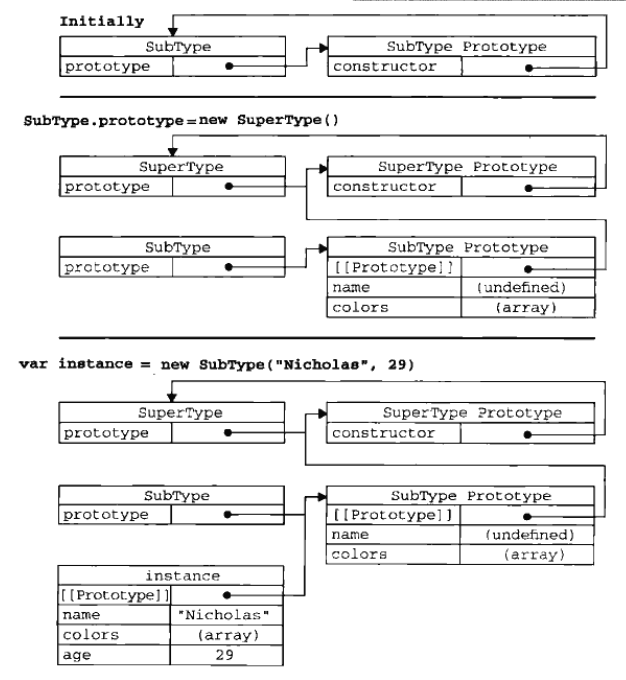
寄生组合式继承:通过借用构造函数的来继承属性,通过原型链的混成形式来继承办法。
不必为了指定子类的原型而调用父类的构造函数,我们所需要的无非就是父类原型的一个副本。本质上,使用寄生式继承来继承父类的原型,然后再讲结果指定给子类的原型。
|
|
只调用一次父类构造函数,原型链保持不变,正常使用instanceof 和isPrototypeOf
每天一道编程题——判断t1树是否包含t2树的全部拓扑结构
原理:
遍历t1树,然后将其每个子树与t2作比较。最后把所有结果进行或运算即可。
复杂度:
O(N*M) t1节点数N;t2节点数M
|
|
每天一道编程题——二叉树的序列化和反序列化
二叉树被记录成文件的过程称为二叉树的序列化
同通过文件重建二叉树的过程称为二叉树的反序列化
方法一:
通过先序遍历实现序列化和反序列化
建立string,先序遍历二叉树,如果遇到null节点,就在string的末尾加上”#!”,”#”表示这个节点为空,”!”表示一个值的结束。对于不为空的节点,假设3,则为”3!”
|
|
方法二:
通过层次遍历12345678910111213141516171819202122232425262728293031323334353637383940def serialByLevel(head):if head == None: return '#!'string = str(head.value) + '!'queue = deque()queue.append(head)while len(queue) != 0: head = queue.popleft() if head.left is not None: string += str(head.left.value) + '!' queue.append(head.left) else: string += '#!' if head.right is not None: string += str(head.right.value) + '!' queue.append(head.right) else: string += '#!'return stringdef reconByLevelString(levelStr):def generateNodeByString(val): return Node(int(val)) if val != '#' else Nonevalues = levelStr.split('!')queue = deque()index = 0head = Node(values[index])index += 1if head is not None: queue.append(head)while len(queue) != 0: node = queue.popleft() node.left = generateNodeByString(values[index]) index += 1 node.right = generateNodeByString(values[index]) index += 1 if node.left is not None: queue.append(node.left) if node.right is not None: queue.append(node.right)return head
每天一道编程题——最长递增子序列
|
|
getdp函数的复杂度太高,我们尝试下将其降到O(NlogN)
我们利用二分查找的思想
我们试着用一个数组ends保存,在所有长度为i的递增序列中,最小的结尾数为ends[i-1]
初始化一个ends[]和一个int型right,并规定ends[0,…,right]为有效区,否则为无效区
遍历arr,假设当前为i,
在ends的有效区从最左边开始找,找到大于arr[i]的数,则表示arr[i]结尾的最长递增序列长度=right+1
最后还有修改ends对应的值为arr[i],以便下次遍历
如
arr = [2, 1, 5, 3, 6, 4, 8, 9, 7]
ends[0]=arr[0]=2
right=0
i=1,ends有效区=[2]
从左开始,ends[0]>arr[1],
表示arr[i]结尾的最长递增序列长度=right+1=1,
ends[0]=arr[1]=1
i=2,ends有效区=[1]
从左开始,ends[0]<arr[2],
没有发现,最长递增序列长度=right+1=2
right++
ends[right]=arr[2]
i=3,ends有效区=[1,5]
从左开始,ends[1]>arr[3],
表示arr[i]结尾的最长递增序列长度=right+1=2,
ends[0]=arr[3]=3
i=4,ends有效区=[1,3]1234567891011121314151617181920def getdp2(arr): n = len(arr) dp, ends = [0] * n, [0] * n ends[0], dp[0] = arr[0], 1 right, l, r, m = 0, 0, 0, 0 for i in range(1, n): l = 0 r = right # 二分查找,若找不到则ends[l或r]是比arr[i]大而又最接近其的数 # 若arr[i]比ends有效区的值都大,则l=right+1 while l <= r: m = (l + r) / 2 if arr[i] > ends[m]: l = m + 1 else: r = m - 1 right = max(right, l) ends[l] = arr[i] dp[i] = l + 1 return dp
别小看了从O(N^2)到O(NlogN)
在8000的规模下
算法1和算法2的运行时间为8.28299999237和0.0190000534058
两者相差436倍!!
Python设计模式——外观模式(门面模式)
假设你去买东西,你肯定是问店主,因为店主对这家店的货物分布比你熟悉,然后店主把你需要的东西交给你,就这么简单。
/interface-800x392.png)
要求一个子系统的外部与其内部的通信必须通过一个统一的对象进行。外观模式提供一个高层次的接口,使得子系统更易于使用。
It provides a unified interface to a set of interfaces in a subsystem and defines a highlevel interface that helps the client use the subsystem in an easy way.
除了这个接口不允许有任何访问子系统的行为发生。
Facade门面角色:客户端可以调用这个角色的方法。次角色知晓子系统的所有功能和责任。一般情况下,本角色会将所有从客户端发来的请求委派到相应的子系统去,也就是说该角色没有实际的业务逻辑,只是一个委托类。
subsystem子系统角色:每一个子系统都不是一个单独的类,而是一个类的集合。子系统不知道门面的存在。对于子系统而言,门面仅仅是另外一个客户端而已。
实现代码
|
|
优点
- 减少了系统的相互依赖。所有的依赖都是对门面对象的依赖,与子系统无关
- 提高灵活性,不管子系统内部如何变化,只要不影响到门面对象,任你自由活动
- 提高安全性
缺点
- 不符合开闭原则,对修改关闭,对扩展开放。唯一能做的就只有修改门面角色的代码。
场景
- 为一个复杂的模块或子系统提供一个供外界访问的接口
- 子系统相对独立——外界对子系统的访问只要黑箱操作即可
注意事项
- 一个子系统可以有多个门面
- 门面不参与子系统内的业务逻辑
- 门面只是提供一个访问子系统的一个路径,它不应该也不能参与具体的业务逻辑,否则会产生一个倒依赖的问题:子系统必须依赖门面才能被访问。
- 门面不能常变,而业务常变
- 解决方法,可以将具体的业务封装在一个类中,封装完毕后提供给门面对象调用。(试下修改代码中的arrange?)
Python设计模式——工厂方法模式
简单工厂模式
UML图
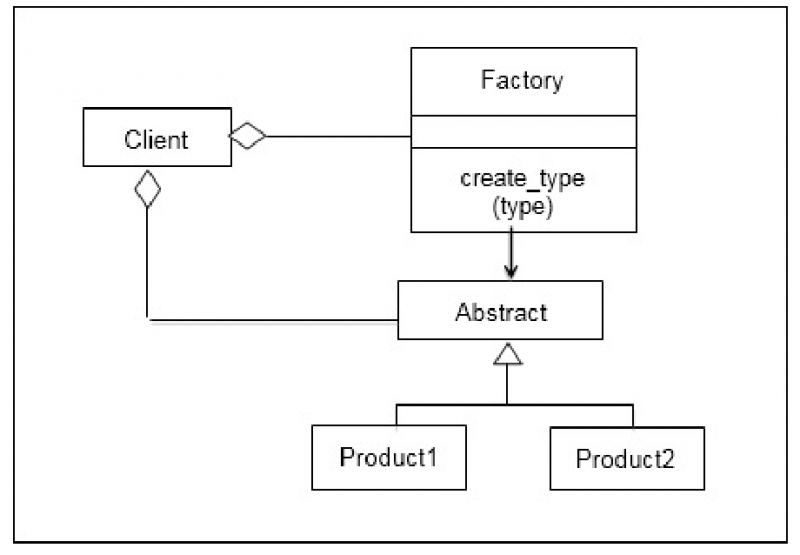
当Client调用Factory的create_type方法,Factory会根据传递的参数,生产出Product1或Product2
工厂方法模式
定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。
define an interface to create objects, but instead of the factory being responsible for the object creation, the responsibility is deferred to the subclass that decides the class to be instantiated.
抽象产品类Product负责定义产品的共性,实现对事物最抽象的定义;
Creator为抽象创造类,也就是抽象工厂,具体如何创建产品类是由具体的实现工厂ConcreteCreator完成的。
UML图
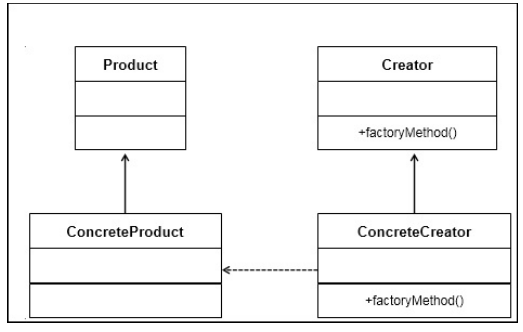
实现代码
|
|
对比简单工厂模式,你就会发现,两者的不同在于工厂方法模式多了一个抽象工厂类(在此例中为Profile)。所以“定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。”
优点
- 良好的封装性。一个对象创建时有条件约束的,如一个调用者需要一个具体的产品对象,只要知道这个产品的类名(或者约束字符串)就可以了。屏蔽了产品类。
- 扩展性优秀。只要扩展一个工厂类就行。
- 解耦
工厂方法模式是new一个对象的代替品,但需要考虑其增加代码复杂度的成本。
例如设计一个连接邮件服务器的框架,把POP3,IMAP,HTTP三种连接方式作为产品类。
定义一个工厂方法,根据不同的传入条件,产生不同的产品类,从而选择不同的连接方式。
抽象工厂模式
UML图
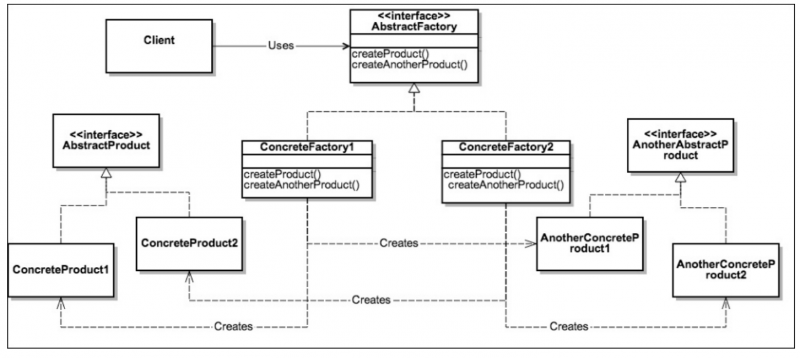
Product1与Product2是由关联的,而其又分别从两个工厂生产出来的,用户通过使用抽象工厂的接口,指挥具体的工厂生产出产品
实现代码
|
|
工厂方法和抽象工厂方法的不同
| 工厂方法 | 抽象工厂方法 |
|---|---|
| 把创造产品的方法暴露给客户 | 包含一个或多个工厂方法,来创造有关联的产品 |
| 子类决定实例化哪一个类 | 使用合成来委托 |
| 工厂方法用来创建一个对象 | 创造一个有关联的产品族 |
抽象工厂方法,增加产品族非常难。这要更改AbstractCreator,增加一个createProduct,然后其余的createProduct都要一同更改。
但是增加产品还是很方便的,比如我们增加一个海鲜披萨?
但涉及跨平台的时候,各个操作系统上的软件功能,应用逻辑,UI都大致相似,我们需要的是使用抽象工厂模式屏蔽掉操作系统对应用的影响,调用不同的工厂方法,由不同的产品类去处理与操作系统交互的信息。
每天一道编程题——换零钱的方法数
给定数组arr,arr中所有的值都为正数且不重复。每个值代表一种面值的货币,每种面值的货币可以使用任意张,在给定一个整数aim代表要找的钱,求换钱有多少种方法。
如
arr=[1,5,10,25],aim=0,返回1
arr=[1,5,10,25],aim=15,返回6
arr=[3,5],aim=2,返回0
暴力递归破解法
如果arr=[5,10,25,1],aim=15
1.用0张5元货币,让[10,25,1]组成剩下的15,最终方法数记为res1
2.用1张5元货币,让[10,25,1]组成剩下的10,最终方法数记为res2
3.用2张5元货币,让[10,25,1]组成剩下的5,最终方法数记为res3
4.用3张5元货币,让[10,25,1]组成剩下的0,最终方法数记为res41234res1:2(0*5+15*1;0*5+1*10+1*5)res2:2(1*5+10*1;1*5+1*10)res3:1(2*5+5*1)res4:1(3*5)
答案就是res1+res2+res3+res4
缺点:
大量重复计算。
规模小的时候还好,一旦规模大了。
比如aim=1000,对于05+110和25+010,后续的计算都是一样的,求[25,1]组合剩下的990的方法总数。
复杂度:
O(aim^N)
|
|
经过记忆搜索优化的暴力递归
又如上面aim=1000的例子。
对于0*5+1*10和2*5+0*10,他们调用递归函数时候传入的参数,arr,aim,index都是相同的,也就是说我们可以利用这一性质去除重复的计算。
记忆搜索优化是针对暴力递归最初级的优化技巧,分析递归函数的状态可以由那些变量表示,做出相应维度和大小的cache即可。
复杂度:
O(N*aim^2)
|
|
关于记忆搜索优化,可见记忆体化的装饰器。
动态规划
|
|
|
|
动态规划的优化(什么?还能优化?)
我们将目光放在前一个算法的第二个while循环里面。
本质上,while里面的枚举可以化简为dp[i][j]=dp[i-1][j]+dp[i][[j-arr[i]] (上边的加上左边的)
如,123arr = [5, 10, 25, 1]aim = 25![1][25]=dp[0][25](./每天一道编程题——换零钱的方法数只用5块)+dp[i][[j-arr[i]](用5块跟10块组成j-arr[i]元的方法数)
复杂度:
O(N*aim)
|
|
空间压缩
将空间复杂度降为O(aim)
|
|