Hello, Web
现在,我们开始编写一个简单的Web服务器,基本思路如下:
- 等到别人连接到我们的服务器并发送HTTP请求
- 分析请求
- 搞清楚要回复什么
- 从数据库中获取数据
- 生成HTML文件
- 发送回去
Python有一个叫BaseHTTPServer的内置模块可以完成第1,2,6步的工作。在下面的例子中,我们只需要完成3~5步就可以了
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler): Page = '''\ <html> <body> <p>Hello, web!</p> </body> </html> ''' def do_GET(self): self.send_response(200) self.send_header("Content-type", "text/html") self.send_header("Content-Length", str(len(self.Page))) self.end_headers() self.wfile.write(self.Page)
|
BaseHTTPRequestHandler类接收HTTP请求并决定使用什么方法处理请求。如果请求方法是GET,将会调用do_GET方法。我们的类RequestHandler重载了BaseHTTPRequestHandler。字符串变量Page 里面存放着我们回复客户端的HTML文档;方法send_response返回状态码200;方法send_header添加HTML头;方法end_headers插入一空行,分割头部跟页面。
1 2 3 4
| if __name__ == '__main__': serverAddress = ('', 8080) server = BaseHTTPServer.HTTPServer(serverAddress, RequestHandler) server.serve_forever()
|
serverAddress 是个包含服务器地址跟端口的tuple,服务器地址为空字符串代表“本机”。然后我们创造BaseHTTPServer.HTTPServer的实例,然后运行。
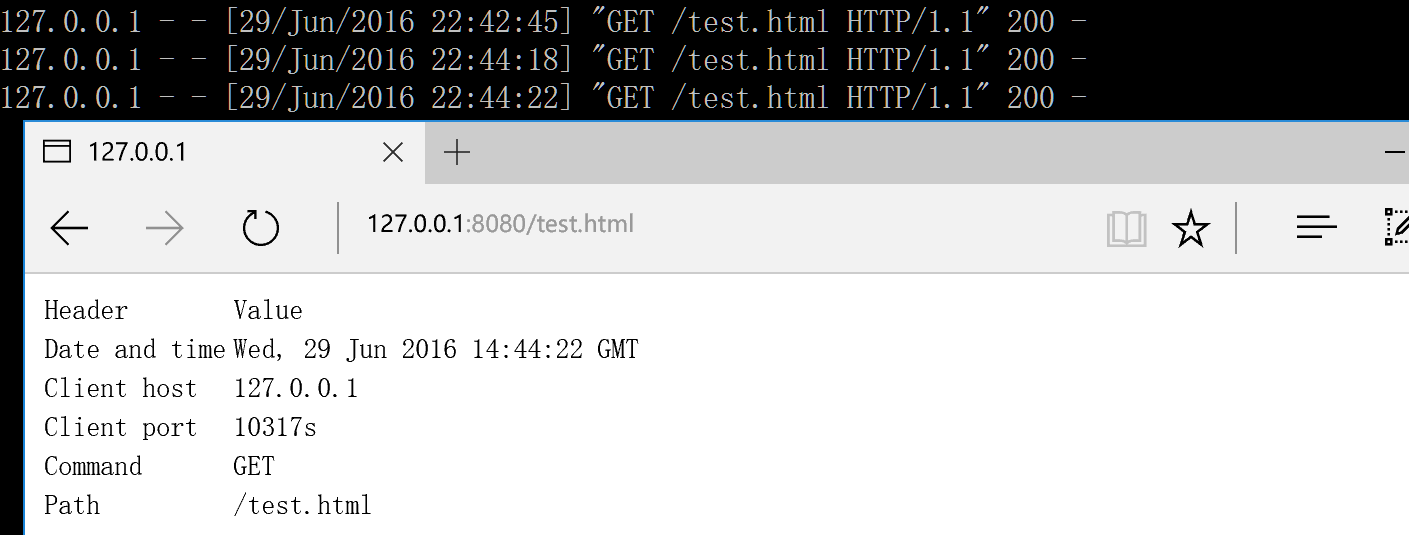
运行效果
更进一步
我们一般很少用到完全静态的HTML文档。一般来说,都是用模板生成HTML文档。
Page就是我们的模板`
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| Page = '''\ <html> <body> <table> <tr> <td>Header</td> <td>Value</td> </tr> <tr> <td>Date and time</td> <td>{date_time}</td> </tr> <tr> <td>Client host</td> <td>{client_host}</td> </tr> <tr> <td>Client port</td> <td>{client_port}s</td> </tr> <tr> <td>Command</td> <td>{command}</td> </tr> <tr> <td>Path</td> <td>{path}</td> </tr> </table> </body> </html> '''
|
我们不妨上面的do_GET方法分开,分成生成跟发送两部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
| class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler): def do_GET(self): page = self.create_page() self.send_page(page) def create_page(self): pass def send_page(self, page): pass def send_page(self, page): self.send_response(200) self.send_header("Content-type", "text/html") self.send_header("Content-Length", str(len(page))) self.end_headers() self.wfile.write(page) def create_page(self): values = { 'date_time' : self.date_time_string(), 'client_host' : self.client_address[0], 'client_port' : self.client_address[1], 'command' : self.command, 'path' : self.path } page = self.Page.format(**values) return page if __name__ == '__main__': serverAddress = ('', 8080) server = BaseHTTPServer.HTTPServer(serverAddress, RequestHandler) server.serve_forever()
|
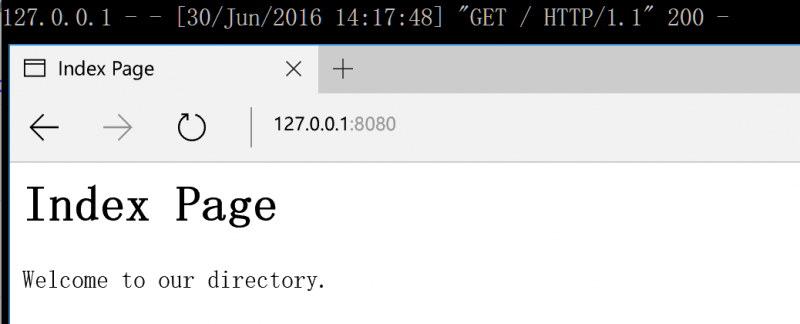
运行效果
注意到,就算我们目录下没有“test.html”这个文件,也不会遇到404错误。
提供静态页面服务
下一步,我们要编写一个真正能够工作的服务器——它会从我们的运行目录里读取任何静态的HTML文件。
分类和处理请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
| def do_GET(self): try: full_path = os.getcwd() + self.path if not os.path.exists(full_path): raise ServerException("'{0}' not found".format(self.path)) elif os.path.isfile(full_path): self.handle_file(full_path) else: raise ServerException("Unknown object '{0}'".format(self.path)) except Exception as msg: self.handle_error(msg) def handle_file(self, full_path): try: with open(full_path, 'rb') as reader: content = reader.read() self.send_content(content) except IOError as msg: msg = "'{0}' cannot be read: {1}".format(self.path, msg) self.handle_error(msg)
|
我们必须还要对错误情况进行处理
显示错误的页面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
| Error_Page = """\ <html> <body> <h1>Error accessing {path}</h1> <p>{msg}</p> </body> </html> """ def handle_file(self, full_path): try: with open(full_path, 'rb') as reader: content = reader.read() self.send_content(content) except IOError as msg: msg = "'{0}' cannot be read: {1}".format(self.path, msg) self.handle_error(msg) def handle_error(self, msg): content = self.Error_Page.format(path=self.path, msg=msg) self.send_content(content, 404) def send_content(self, content, status=200): self.send_response(status) self.send_header("Content-type", "text/html") self.send_header("Content-Length", str(len(content))) self.end_headers() self.wfile.write(content)
|
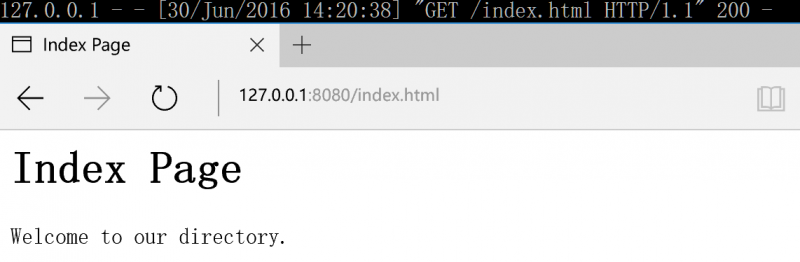
运行效果
监听目录
下一步,我们编写一个可以显示文件列表的服务器(当访问的是文件夹的时候)。或者更深一步,访问文件夹的时候首先看目录下有没有index.html文件,若没有显示文件夹文件列表。
我们重写了do_GET方法
分类和处理请求
1 2 3 4 5 6 7 8 9 10 11 12
| def do_GET(self): try: self.full_path = os.getcwd() + self.path for case in self.Cases: if case.test(self): case.act(self) break except Exception as msg: self.handle_error(msg)
|
首先我们计算请求的物理路径。接下来的代码跟之前有很大不同,通过遍历Cases列表。每一个case都是一个只有两个方法(test,判断是否能处理请求;act,处理请求)的object。我们将self作为参数传进去test和act方法作进一步的处理。这里的self指的是RequestHandler实例(别忘了,我们是在编写RequestHandler的方法do_GET)
下面是case类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
| class case_no_file(object): '''文件或目录不存在''' def test(self, handler): return not os.path.exists(handler.full_path) def act(self, handler): raise ServerException("'{0}' not found".format(handler.path)) class case_existing_file(object): '''文件存在''' def test(self, handler): return os.path.isfile(handler.full_path) def act(self, handler): handler.handle_file(handler.full_path) class case_directory_index_file(object): '''处理目录下的index.html文件''' def index_path(self, handler): return os.path.join(handler.full_path, 'index.html') def test(self, handler): return os.path.isdir(handler.full_path) and \ os.path.isfile(self.index_path(handler)) def act(self, handler): handler.handle_file(self.index_path(handler)) class case_directory_no_index_file(object): '''如果没有index.html,列出目录文件列表''' def index_path(self, handler): return os.path.join(handler.full_path, 'index.html') def test(self, handler): return os.path.isdir(handler.full_path) and \ not os.path.isfile(self.index_path(handler)) def act(self, handler): handler.list_dir(handler.full_path) class case_always_fail(object): '''最底层的case类,处理其他case不能处理的情况''' def test(self, handler): return True def act(self, handler): raise ServerException("Unknown object '{0}'".format(handler.path))
|
前面提到,在do_GET方法里面,将RequestHandler的实例作为handler参数传进去。在act方法里面调用RequestHandler(在act函数里面,handler就是RequestHandler的实例)的方法(如list_dir,handle_file等)进行处理。
然后,我们把RequestHandler类完善一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67
| class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler): Cases = [case_no_file(), case_existing_file(), case_directory_index_file(), case_directory_no_index_file(), case_always_fail()] Error_Page = """\ <html> <body> <h1>Error accessing {path}</h1> <p>{msg}</p> </body> </html> """ Listing_Page = '''\ <html> <body> <ul> {0} </ul> </body> </html> ''' def do_GET(self): try: self.full_path = os.getcwd() + self.path for case in self.Cases: if case.test(self): case.act(self) break except Exception as msg: self.handle_error(msg) def handle_file(self, full_path): try: with open(full_path, 'rb') as reader: content = reader.read() self.send_content(content) except IOError as msg: msg = "'{0}' cannot be read: {1}".format(self.path, msg) self.handle_error(msg) def list_dir(self, full_path): try: entries = os.listdir(full_path) bullets = ['<li>{0}</li>'.format(e) for e in entries if not e.startswith('.')] page = self.Listing_Page.format('\n'.join(bullets)) self.send_content(page) except OSError as msg: msg = "'{0}' cannot be listed: {1}".format(self.path, msg) self.handle_error(msg) def handle_error(self, msg): content = self.Error_Page.format(path=self.path, msg=msg) self.send_content(content, 404) def send_content(self, content, status=200): self.send_response(status) self.send_header("Content-type", "text/html") self.send_header("Content-Length", str(len(content))) self.end_headers() self.wfile.write(content)
|
运行结果
CGI协议
当然,大多数人都不想每次添加新的功能都修改服务器的源代码。一般都服务器都支持一套叫做“通用网关接口”的东西,允许Web服务器执行外部程序,并将它们的输出发送给Web浏览器。
CGI。在物理上是一段程序,运行在服务器上,提供同客户端HTML页面的接口。这样说大概还不好理解。那么我们看一个实际例子:现在的个人主页上大部分都有一个留言本。留言本的工作是这样的:先由用户在客户端输入一些信息,如评论之类的东西。接着用户按一下“发布或提交”(到目前为止工作都在客户端),浏览器把这些信息传送到服务器的CGI目录下特定的CGI程序中,于是CGI程序在服务器上按照预定的方法进行处理。在本例中就是把用户提交的信息存入指定的文件中。然后CGI程序给客户端发送一个信息,表示请求的任务已经结束。此时用户在浏览器里将看到“留言结束”的字样。整个过程结束。
假设我们想要服务器在HTML文档里显示本地时间,将其保存为simple.py
1 2 3 4 5 6 7
| from datetime import datetime print '''\ <html> <body> <p>Generated {0}</p> </body> </html>'''.format(datetime.now())
|
我们添加一个case handler
test方法检查目录下的py文件,如果有就可以用RequestHandler的run_cgi方法执行
1 2 3 4 5 6
| class case_cgi_file(object): def test(self, handler): return os.path.isfile(handler.full_path) and \ handler.full_path.endswith('.py') def act(self, handler): handler.run_cgi(handler.full_path)
|
run_cgi核心思想很简单:
- 在子程序中运行程序
- 捕获标准输出
- 把数据发送回客户端
一个完整的CGI协议肯定比这复杂。比如,它要处理URL里面的参数。。。
1 2 3 4 5 6 7
| def run_cgi(self, full_path): cmd = "python " + full_path child_stdin, child_stdout = os.popen2(cmd) child_stdin.close() data = child_stdout.read() child_stdout.close() self.send_content(data)
|
最后,我们把case handler类重写。所有case handler都继承base_case这个case handler基类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
| class base_case(object): def handle_file(self, handler, full_path): try: with open(full_path, 'rb') as reader: content = reader.read() handler.send_content(content) except IOError as msg: msg = "'{0}' cannot be read: {1}".format(full_path, msg) handler.handle_error(msg) def index_path(self, handler): return os.path.join(handler.full_path, 'index.html') def test(self, handler): assert False, 'Not implemented.' def act(self, handler): assert False, 'Not implemented.' case handler class case_no_file(base_case): def test(self, handler): return not os.path.exists(handler.full_path) def act(self, handler): raise ServerException("'{0}' not found".format(handler.path)) class case_cgi_file(base_case): def run_cgi(self, handler): cmd = "python " + handler.full_path child_stdin, child_stdout = os.popen2(cmd) child_stdin.close() data = child_stdout.read() child_stdout.close() handler.send_content(data) def test(self, handler): return os.path.isfile(handler.full_path) and \ handler.full_path.endswith('.py') def act(self, handler): self.run_cgi(handler) class case_existing_file(base_case): def test(self, handler): return os.path.isfile(handler.full_path) def act(self, handler): self.handle_file(handler, handler.full_path) class case_directory_index_file(base_case): def test(self, handler): return os.path.isdir(handler.full_path) and \ os.path.isfile(self.index_path(handler)) def act(self, handler): self.handle_file(handler, self.index_path(handler)) class case_directory_no_index_file(base_case): Listing_Page = '''\ <html> <body> <ul> {0} </ul> </body> </html> ''' def list_dir(self, handler, full_path): try: entries = os.listdir(full_path) bullets = ['<li>{0}</li>'.format(e) for e in entries if not e.startswith('.')] page = self.Listing_Page.format('\n'.join(bullets)) handler.send_content(page) except OSError as msg: msg = "'{0}' cannot be listed: {1}".format(self.path, msg) handler.handle_error(msg) def test(self, handler): return os.path.isdir(handler.full_path) and \ not os.path.isfile(self.index_path(handler)) def act(self, handler): self.list_dir(handler, handler.full_path) class case_always_fail(base_case): def test(self, handler): return True def act(self, handler): raise ServerException("Unknown object '{0}'".format(handler.path))
|