Flody-Warshall算法
求任意两点之间的最短路径。称为“多源最短路径”
## 分析
如果要让任意两点(a到b)之间的路径变短,只能引入第三个点(k),有时候甚至不止一个k
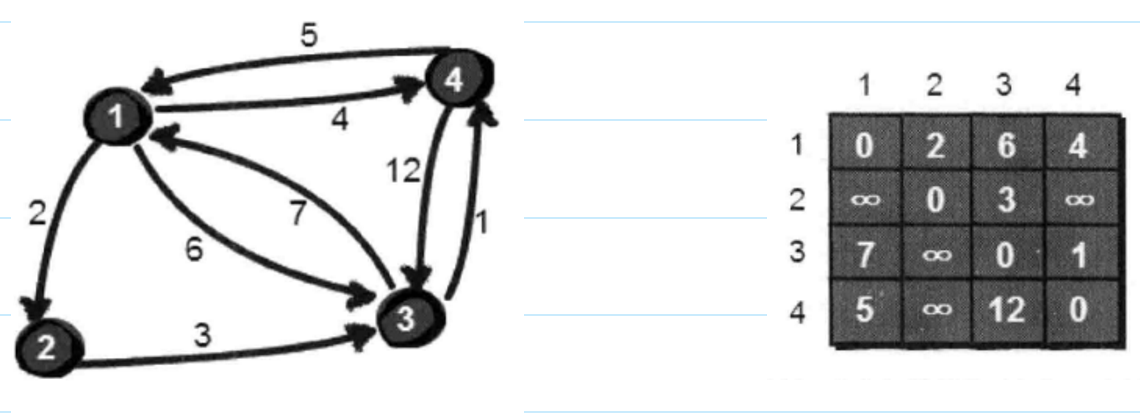
若只允许经过1号顶点。只需判断e[i][1]+e[1][j]是否比e[i][j]要小即可。e[i][j]表示从i号顶点到j号顶点之间的路程。
只允许经过1号顶点
|
|

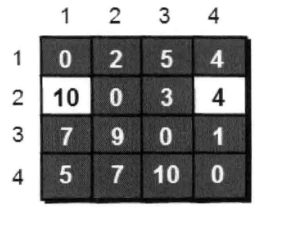
只允许经过1号和2号顶点
|
|

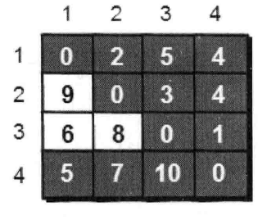
只允许经过1号2号3号顶点
最终
实现代码
|
|
复杂度
时间复杂度:O(N^3)
空间复杂度:O(N^2)
特点
适用于稠密图和顶点关系密切的图
不能解决负权回路
Dijkstra算法

求1到23456最短路径。“单源最短路径”问题
分析
我们建立一个数组dis。用于存放1号顶点到其余各个顶点的距离。

先找出一个离1号顶点最近的顶点。
找出的是2号顶点。
讨论2-3这条路径能否让1到3的路径变短,也就是比较dis[3]和dis[2]+e[2][3]的大小。
可知dis[3]>dis[2]+e[2][3]。我们称为“松弛”
同理2-4,将dis[4]松弛为4
都松弛完毕之后,将2号顶点在book数组中标记起来

接下来在剩下的3456顶点中,选出离1号顶点最短的顶点。
当前离1号顶点最近的是4号顶点。因此dis[4]从“估计值”变为“确定值”
接下来对4号顶点的所有相邻点进行松弛(4-5,4-6,4-3)
都松弛完毕之后,将4号顶点在book数组中标记起来
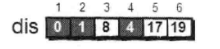
接下来在剩下的356顶点中,选出离1号顶点最短的顶点。
当前离1号顶点最近的是3号顶点。因此dis[3]从“估计值”变为“确定值”
接下来对3号顶点的所有相邻点进行松弛(3-5)
都松弛完毕之后,将3号顶点在book数组中标记起来

接下来在剩下的56顶点中,选出离1号顶点最短的顶点。
当前离1号顶点最近的是5号顶点。因此dis[5]从“估计值”变为“确定值”
接下来对5号顶点的所有相邻点进行松弛(5-6)
都松弛完毕之后,将5号顶点在book数组中标记起来

最后对6号顶点进行松弛

Dijkstra算法的主要思想:通过”边“来松弛1号顶点到其他顶点的距离。
实现代码
|
|
复杂度
时间复杂度:O(N^2)
空间复杂度:O(M)
优化
- 可用堆降低至O(logN)
- 可用邻接表降至O(M+N)logN
邻接表
对于边数M少于N^2的系数图,可以使用相邻接表代替邻接矩阵。使得事件复杂度降至O(M+N)logN
对于M=N^2,O(M+N)logN是要大于O(N^2)的
存入

|
|
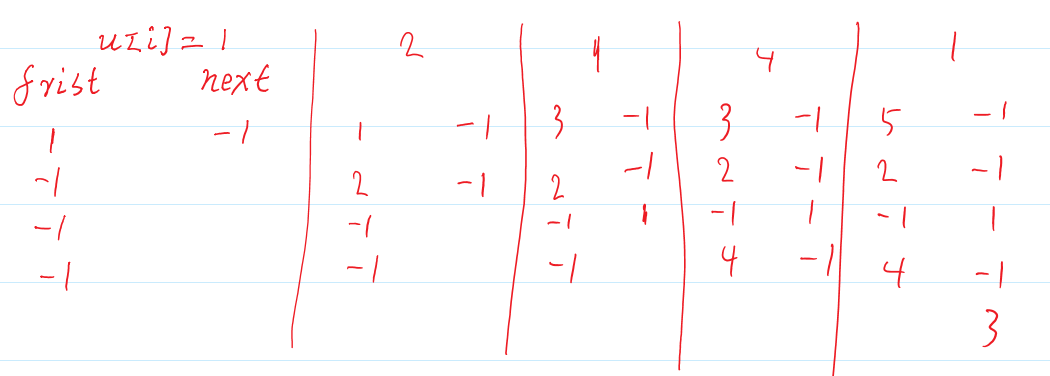
first是存放顶点对应的边数的数组,如果一个顶点有多条边,可以使用next遍历。
如:
顶点1对应有3条边;2,4有1条,3无。
遍历

|
|
Bellman-Ford算法
解决负权边问题
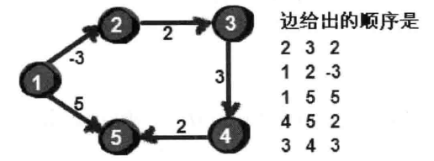
核心代码
v,u,w数组分别一一对应给出的边
n为顶点数,m为边数
分析
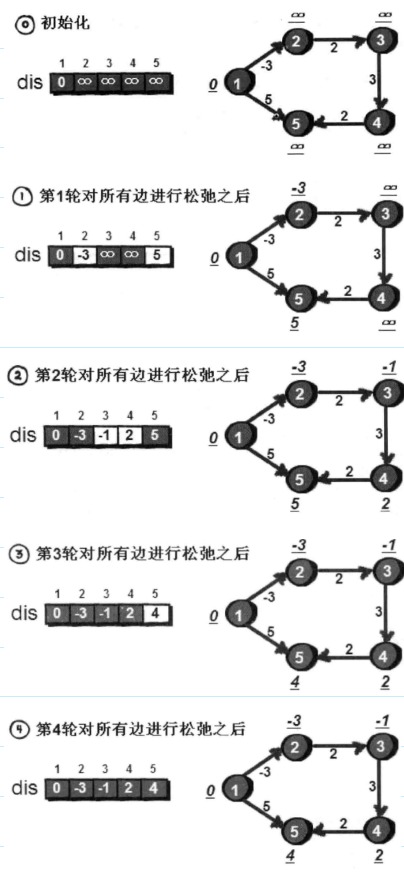
第一轮在对所有的边进行松弛之后,得到的是从1号顶点“只能经过一条边”到达其余各顶点的最短路径长度。
第二轮在对所有的边进行松弛之后,得到的是从1号顶点“最多经过两条边”到达其余各顶点的最短路径长度。
只需进行n-1轮。因为在一个含有n个顶点的图中,任意两点之间的最短路径最多包含n-1边
最短路径肯定是一个不包含回路的简单路径。
回路分为正权回路与负权回路
正权回路:回路权值为正。去掉这个回路会得到更短的路径。
负权回路:回路权值为负。每走一次会得到更短的路径。
Bellman-Ford算法还可以检测一个图是否存在负权回路
如果在进行n-1轮松弛之后,依然存在:
复杂度
时间复杂度:O(NM),比Dijkstra还要高
空间复杂度:O(M)
优化
- Bellman-Ford算法经常会在未到达n-1轮松弛前就已经计算出最短路径。如果在新一轮的松弛中数组dis没有发生变化。就可以跳出循环。
- Bellman-Ford的队列优化每次选取队首顶点u,对顶点u的所有出边进行松弛操作。如,有一条u-v,如果通过u-v这条边使得源点到顶点v的最短路径变短。(dis[u]+e[u][v]<dis[v]),且顶点v不在当前的队列中,就将顶点v放入队尾。我们还需要对队列中的顶点去重对顶点u的所有出边松弛完毕之后,将顶点v出队。
接下来不断从队列中取出新的队首顶点再进行如上操作直至队列为空。
实例分析
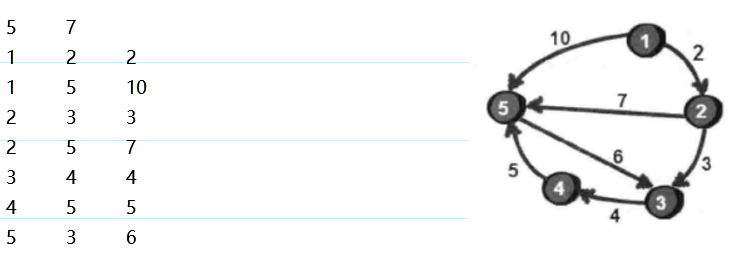
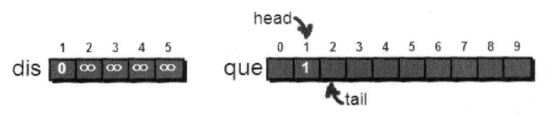
取1-2,dis[1]+e[1][2]<dis[2]。入队
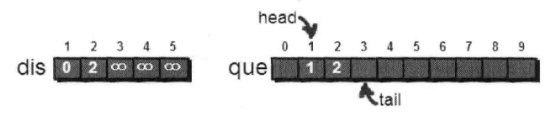
取1-5
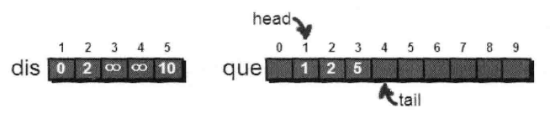
1号顶点处理完毕。出队
取2-3,2-5。处理2-5的时候,由于5号顶点已经在队列中,所以不能再次入队。
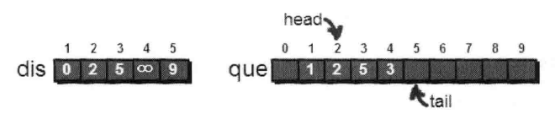
如此类推。最终处理结果

实现代码
本例使用邻接表存储
|
|
队列优化的Bellman-Ford算法:其实上就是只处理那些在前一遍松弛中改变了最短路径估计值的顶点(因为只有这样才可能引起它们的邻接点最短路径估计值发生改变。)
使用队列优化的Bellman-Ford算法在形式上和广度优先搜索非常类似,不同的是在广度优先搜索的时候一个顶点出队后通常就不会再重新进入队列。
当一个顶点的最短路径估值变小后,需要重新进行松弛。
如果某个点进入队列的次数超过n次,则这个图有负环。
复杂度
最坏的情况下为O(NM)